Salesforce Data Loader and
Duplicate Records Management
Set batch size to 1
Problem Statement
The problem to solve is detection of duplicate records that exist
in an input file read by Salesforce Data Loader and updated into
Salesforce. In this scenario duplicate records exist in the input
file; not to be confused with a different scenario, of records in
a Salesforce Data Loader input file that duplicate other records already
in Salesforce. This note is intended to help users with Data
Loader input files (.csv files) that may contain duplicate
records.
If a Data Loader input file has duplicates in it, and batch size
is not set to 1, then duplicate records in that input file may end
up loaded into Salesforce undetected. This will happen regardless
of the duplicate management settings that exist in Setup>
Data> Duplicate Management> Matching Rules.
The Salesforce documentation spells out this issue, in disparate
places, with something less than perfect clarity, as detailed
below from various sources.
Salesforce Data Quality Manual
The Salesforce Data Quality manual
(https://resources.docs.salesforce.com/226/latest/en-us/sfdc/pdf/data_quality.pdf)
on pages 14-16 states:
“Duplicates can be detected when a sales
rep creates, clones, or edits a record and a duplicate rule
runs, or when you run a duplicate job. They can also be detected
as part of other processes, such as importing or an API.”
While this would seemingly suggest duplicates are detected in a
data loader input file, the issue is that records within a batch,
that may have duplicates, are all committed at one time.
Order of Execution in Apex Developer's Guide
In the Apex Developer’s Guide, “Triggers and Order of Execution”
(https://developer.salesforce.com/docs/atlas.en-us.apexcode.meta/apexcode/apex_triggers_order_of_execution.htm),
duplicate checking is sixth the event in sequence:
“When you save a record with
an insert, update, or upsert statement”.
This would also seem to suggest that consecutive duplicates
within a Data Loader input file should be detected. The problem
is, they are not, unless batch size is set to one.
Timing of Saves
There is clarification of this issue on page 18 of Data Quality,
in “Things to know about duplicate rules”:
“Timing of Saves
If multiple records are saved simultaneously and
your duplicate rule is set to block or alert sales reps, those
records aren’t compared with each other. They’re compared only
with records already in Salesforce. This behavior doesn't
affect the Report option, and duplicate record sets do include
records that match other records saved simultaneously.”
… Meaning the timing of saves is such that records
within a batch are not “compared with each other… only compared
with records already in Salesforce”.
Salesforce Duplicate Matching Rules
When using Data Loader to import records, Salesforce Duplicate
Matching Rules compare input records with records ‘already in
Salesforce’. Data Loader commits input records to the Salesforce
database in increments equal to batch size. By setting batch size
to one, input records are committed to the database one at a time.
This allows for detection of duplicate records within a Data
Loader input file.
Data Loader Guide
The default Data Loader batch size is 200. This means records read
by Data Loader are committed to the Salesforce database in
increments of 200 records at one time. If duplicates exist within
that batch of 200 records they are not detected. If batch size is
set to 1, each input record is committed to the database as it is
read. If consecutive input records are duplicates and batch size
is 1, matching rules detect this condition because each input
record is committed to the database before the next record is
inspected.
The Data Loader Guide
(https://developer.salesforce.com/docs/atlas.en-us.dataLoader.meta/dataLoader/data_loader.htm)
spells this out in the explanation of settings:

Data Loader Settings Panel
The Data Loader Settings panel looks like this. Note Batch size is
the second field:
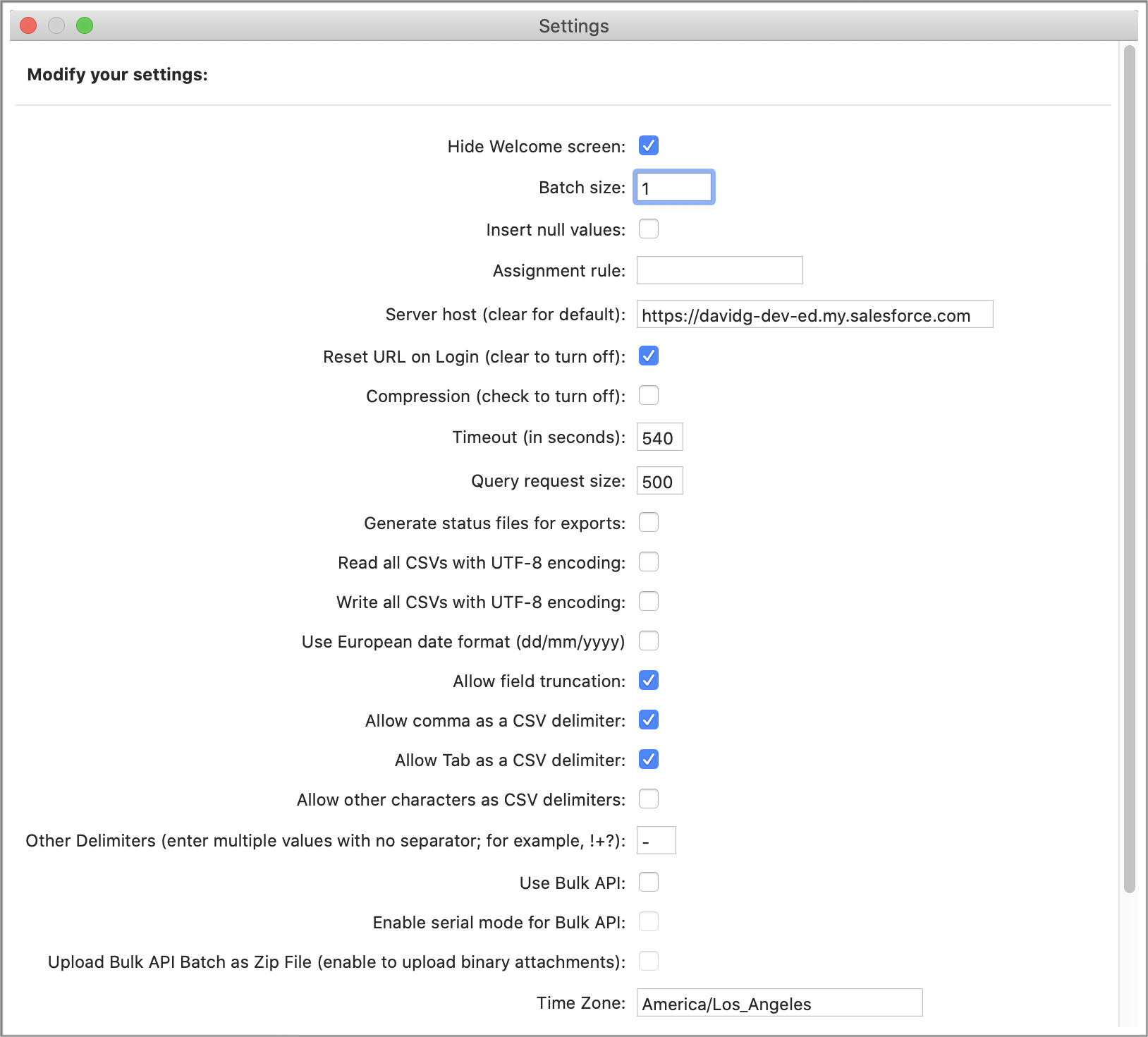
If batch size is set to one then duplicate records within a Data
Loader input file are detected. Users will need to look at the
success, error, and log files that are created by Data Loader to
see all results of the run.
Calls to the Salesforce Help Desk
I first encountered this some time ago when teaching a class about
duplicate management in Salesforce. During class a student
promptly proved me wrong, by importing a small list of duplicate
contacts with Data Loader. I raised the issue with the Salesforce
help desk, and after some back-and-forth via phone and email it
was explained how and why batch size must be set to one to correct
this issue. It was also explained that large batch size improves
performance, and setting batch size to one will induce a
performance penalty. There is a separate
paper quantifying the scope and scale of this performance
degradation, which is significant.
Since then I have seen other users and companies occasionally
encounter this issue, so I wrote this note. I hope it is helpful.